
Q-learning (калькированный термин — Q-обучение) — это один из алгоритмов реализации метода машинного обучения с подкреплением (reinforcement learning, RL).
Рассмотренный далее пример «Q-learning in action» может оказаться полезным для новичков в этой области.
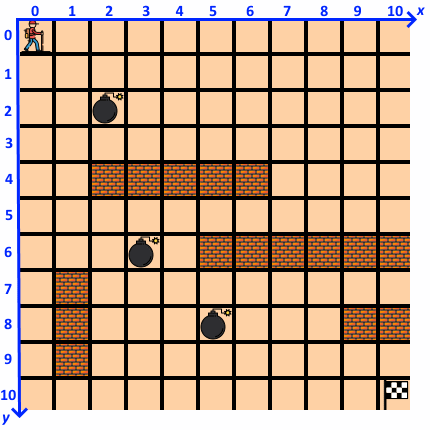
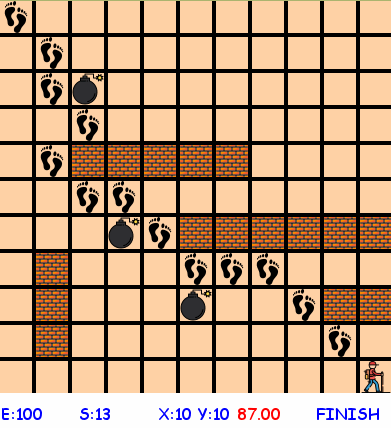
Человечек (агент, agent) ![]() живет в плоском мире размером 11 на 11 клеток (environment):
живет в плоском мире размером 11 на 11 клеток (environment):
Агент может пошагово совершать действия, а каждое действие (action) заключается в попытке перемещения на соседнюю клетку по любому из 8 направлений:
(«попытке», так как выход за границы мира запрещен — можно считать, что граница «выталкивает» агента в прежнюю позицию):
В мире агента имеются стены ![]() , которые не пускают агента на занятые ими клетки, и ловушки
, которые не пускают агента на занятые ими клетки, и ловушки ![]() , «телепортирующие» агента в начальную позицию.
, «телепортирующие» агента в начальную позицию.
Состояние (state) агента на каждом шаге (step) описывается его позицией — порядковым номером клетки:

Стартовая позиция агента в начале эпизода (episode) — верхний левый угол, цель агента — достичь конечной позиции — правого нижнего угла ![]() по кратчайшему пути.
по кратчайшему пути.
Вся прелесть алгоритма Q-learning в том, что он работает тогда, когда агент даже и не знает КАК добиться желаемого результата («model-free»).
Выбор оптимальных действий агента в этом случае описывается Марковским процессом принятия решений (MDP Markov Decision Process).
Для успешного применения такого метода необходим механизм обратной связи агента со средой — вознаграждение (reward), которое может быть положительным, отрицательным или нулевым.
За каждый ход агент получает отрицательную награду (-1) — стимулирует агента сокращать число сделанных ходов, а за достижение конечной точки — положительную награду (+100) — стимулирует агента перейти в эту точку.
При достаточно длительном процессе обучения алгоритм обучения с подкреплением позаботится о максимизации вознаграждения, получаемого агентом.
Этот механизм похож на механизм формирования условного рефлекса.
Я реализовал проект на Python в связке с Pygame для большей зрелищности процесса обучения.
Исходный код проекта доступен на GitHub под лицензией GNU GPL 3 — https://github.com/Dreamy16101976/QL .
Текст программы, обильно снабженный комментариями, содержится в файле ql.py.
Настройки описаны в файле settings.py:
гиперпараметры:
ALPHA = 1.0 # скорость обучения GAMMA = 0.95 # коэффициент учета последующих наград
стены:
WALLS = {(2,4), (3,4), (4,4), (5,4), (6,4), (10,8), (9,8), (10,6), (9,6), (8,6), (7,6), (6,6), (5,6), (1,7), (1,8), (1,9)}
ловушки:
TRAPS = {(2,2), (3,6), (5,8)}
После запуска программа запрашивает количество реализуемых эпизодов:
![]()
Затем начинается обучение агента, в процессе которого точки, где побывал агент, помечаются следами :
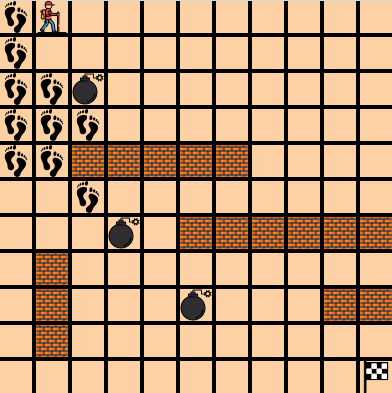
При обучении происходит заполнение ячеек Q-таблицы. Q-таблица ставит в соответствие действиям, которые выполняются в том или ином состоянии агента, число (q-value), характеризующее «полезность» этого действия для агента. При этом учитывается не только сиюминутная награда за это действие, но и награды, получаемые агентом в дальнейшем. После каждого шага обновляется ячейка таблицы, соответствующая выполненному действию, с помощью уравнения Белмана (Bellman equation).
В конце каждого эпизода в консоли отображаются оптимальные варианты действий: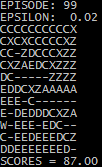
На последнем эпизоде выполняется проверка — тестовое путешествие агента, в котором он опирается только на составленную ранее Q-таблицу — выбирает на каждом шаге действие, которому соответствует максимальное значение в таблице в таблице для текущего состояния (т.н. ординалистский подход к моделированию поведения и выбора).
После обучения в течение 99 эпизодов агент уверенно находит оптимальный маршрут:
Англоязычная версия статьи — https://www.reddit.com/r/Python/comments/e4isiy/qlearning_in_action_or_machine_learning_with/
Продолжение следует