
Q-learning (калькированный термин — Q-обучение) — это один из алгоритмов реализации метода машинного обучения с подкреплением (reinforcement learning, RL).
Рассмотренный далее пример «Q-learning in action» может оказаться полезным для новичков в этой области.
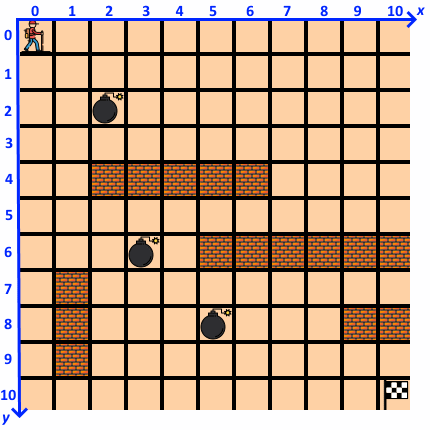
Человечек (агент, agent) ![]() живет в плоском мире размером 11 на 11 клеток (environment):
живет в плоском мире размером 11 на 11 клеток (environment):
Агент может пошагово совершать действия, а каждое действие (action) заключается в попытке перемещения на соседнюю клетку по любому из 8 направлений:
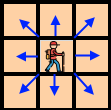
(«попытке», так как выход за границы мира запрещен — можно считать, что граница «выталкивает» агента в прежнюю позицию):
В мире агента имеются стены ![]() , которые не пускают агента на занятые ими клетки, и ловушки
, которые не пускают агента на занятые ими клетки, и ловушки ![]() , «телепортирующие» агента в начальную позицию.
, «телепортирующие» агента в начальную позицию.
Состояние (state) агента на каждом шаге (step) описывается его позицией — порядковым номером клетки:

Стартовая позиция агента в начале эпизода (episode) — верхний левый угол, цель агента — достичь конечной позиции — правого нижнего угла ![]() по кратчайшему пути.
по кратчайшему пути.
Вся прелесть алгоритма Q-learning в том, что он работает тогда, когда агент даже и не знает КАК добиться желаемого результата («model-free»).
Мое баловство с Q-learning или ML + Python + Pygame
Добавить комментарий